Weekly Coding Challenge
Every week, we pick a real-life project to build your portfolio and get ready for a job. All projects are built with ChatGPT as co-pilot!
Start the ChallengePodcast: Code Sets You Free
A tech-culture podcast where you learn to fight the enemies that blocks your way to become a successful professional in tech.
Listen the podcastMastering Databases: What is SQL Database
What is SQL?
SQL (Structured Query Language) is the language most commonly used when you want to talk directly to a database. It allows you to store, manipulate and retrieve data that is stored in relational databases.
The SQL query syntax looks like this:
1SELECT username FROM user WHERE email='info@breatheco.de'
☝ In this example, we request from the database all users with an email address equal to "info@breatheco.de".
If you want to earn the respect of a developer, you need to get comfortable with SQL. You will use it A LOT when working with data.
Origins of SQL and Databases
In a world in which the presence of data is becoming more and more important due to its significant impact on decision-making and the proliferation of business processes guided by data and information, databases are the best way to store them. In fact, a fundamental component of Industry 4.0 is precisely this technology. From data, we will be able to carry out Data Mining, Machine Learning and automation processes, but everything starts with databases.
The origin of databases was the .txt and .csv files, which, although they allowed storing a large amount of information, it made the data easy to corrupt and difficult to access.

Faced with this scenario, at some point, a scientist would propose a way to do things better, and it was Edgar who decided to redesign those files and create a standard way of storing data in files focused on performance and integrity. He teamed up with Donald, and together they created a language called SQL, which was designed to work with data in a very user-friendly way.
Components of a database
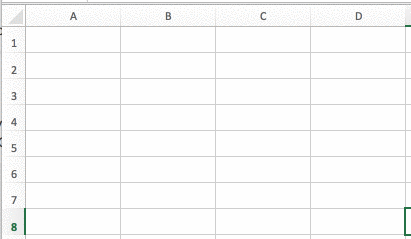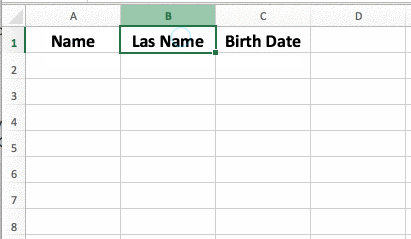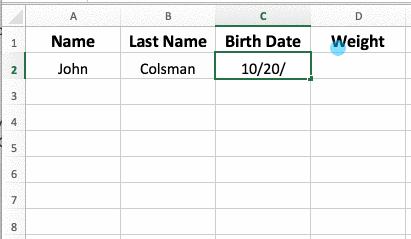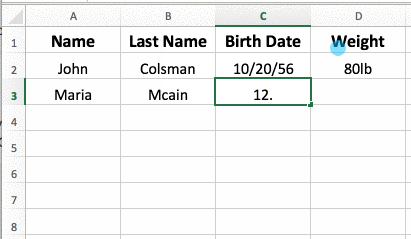
Databases are similar in appearance to spreadsheets: everything is stored in tables with rows and columns. Each column represents common attributes in the rows they intersect, which are instances of data.
1. Tables
In a database, a "table" is an information entity with "People", "Cars", "Events", etc. The rows contain the information related to the characteristics, each row being a column. So, if we have a table called "People", it may contain columns for "First name", "Last name", "ID", etc. A row would have the values corresponding to a person. For example, a row could be "Luis", "Perez Gomez", "123456789Z". The "table" is the only structure capable of storing data via SQL.
2. Rows
A table is composed of a set of "rows". Each row is an instance of information. So, in the example above, each of the rows would be a specific person that we have stored in our database.
3. Columns
A table is also composed of a set of "columns". Each of them is a characteristic of the table itself. So, in the example above, each of the characteristics of the person will be their First Name, Last Name and ID. Each characteristic will have a specific type of value associated with it (string, integer, boolean, etc.).
A table can contain a large set of rows and columns. The access and query execution times will depend on its size.
Relationships between tables
A database is a collection of interconnected tables. The connection between two tables is called a "relationship" and can be one of the following:
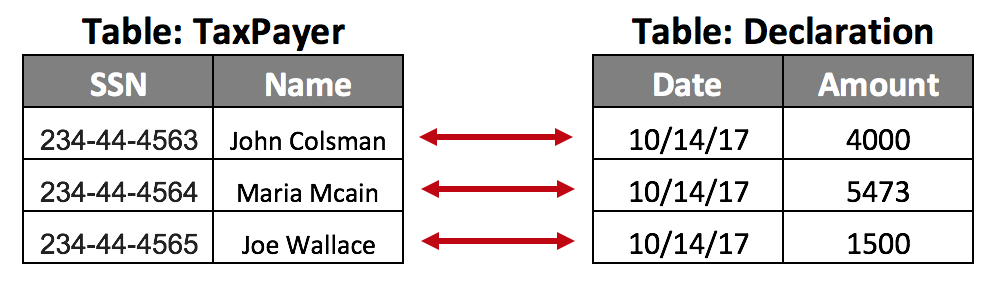
One to one:
The perfect example is the social security database. Probably this database has a table called TaxPayer that contains all the information about each person with a social security number and another table with the current year's Tax Returns: A person can have only one return, and only one return can be made by a person.
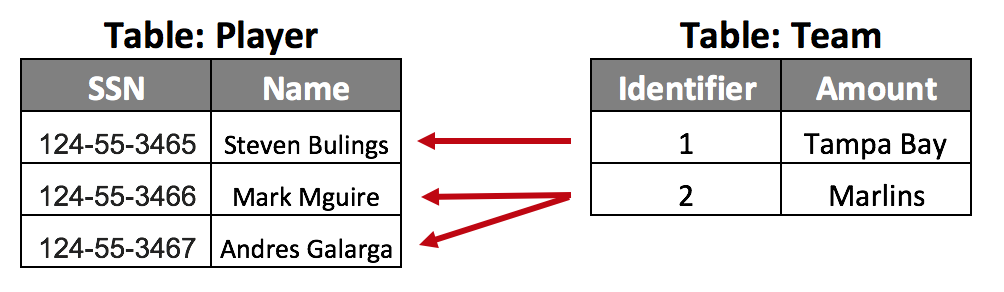
One to many:
The Major League Baseball database probably has a table called Players (with a list of all active players) and another table called Teams (with a list of all active teams). Both tables are connected because one team has many players, but a player can be on only one team.
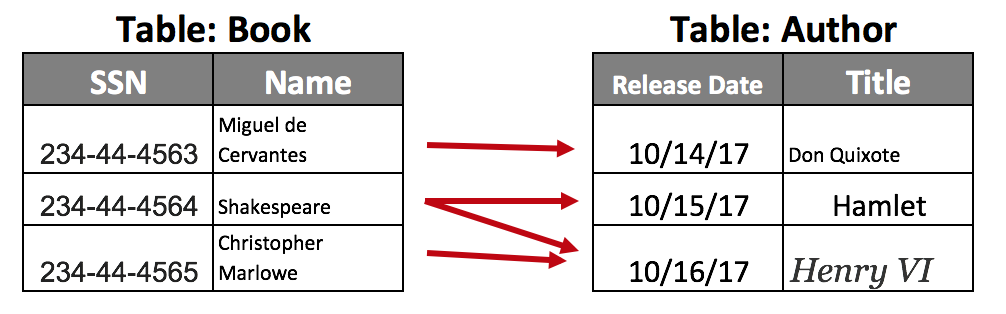
Many to many:
A public library database probably has a table called Author (which contains the information of all authors with published books), and also another table with ALL Books that have been published. Both tables are related because one author can have many books, and one book can have many authors.
SQL syntax
Manipulating tables
There are 3 main operations that can be performed on a table: create, update, or delete. In SQL, these operations are called CREATE, ALTER and DROP. Remember that these operations are used to manipulate the structure of the database, not the information it contains.
CREATE:
Creates a new table, a view of a table, or other object in the database.
1CREATE TABLE IF NOT EXISTS `chat_group` ( 2 `chat_group_id` int(10) UNSIGNED NOT NULL, 3 `name` varchar(20) NOT NULL, 4 `create_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, 5 PRIMARY KEY(`chat_group_id`) 6) ENGINE=InnoDB DEFAULT CHARSET=latin1;
ALTER:
Modifies an existing database object, such as a table.
1ALTER TABLE table_name MODIFY column_name datatype NOT NULL;
DROP:
Deletes an entire table, a view of a table, or other object in the database.
1DROP TABLE customers;
Manipulating data
When using SQL, there are 4 main commands for manipulating data: SELECT, INSERT, UPDATE and DELETE.
All of these commands are designed to manipulate ONE or SEVERAL database records/rows at the same time. But, you can only execute ONE command at a time.
SELECT:
This is the most commonly used operation. It is the only way to retrieve any specific row/record of data from a database. We can specify which rows we want to retrieve by requesting a set of conditions that those rows must meet.
1SELECT column1, column2... columnN FROM table1 WHERE column1 = 3; 2 3// Select a particular user by his Social Security Number 4SELECT ssn, username, email 5FROM user 6WHERE ssn = '233-34-3453';
INSERT:
Creates a new row/record in the table. It will be added at the end.
1INSERT INTO table_name (column1,column2,...columnN) VALUES (value1,value2,...valueN); 2 3// Insert a particular user 4INSERT INTO user (ssn, username, email) 5VALUES ('234-45-3342', 'alesanchezr', 'a@breatheco.de');
UPDATE:
Updates a record or a row in a specific table. It is necessary to provide one or more conditions to identify the specific rows we want to update.
1UPDATE table_name SET column1 = value1 WHERE [condition] 2 3// Updating the email of a user 4UPDATE user 5SET email = 'new@breatheco.de' 6WHERE ssn = '333-44-5534'
DELETE:
Works very similarly to UPDATE, but instead of passing the new values of the new columns you want to update, we only need to specify which rows we want to delete by requesting a set of conditions.
1DELETE FROM table_name WHERE [condition] 2 3// Delete all users (the condition is optional) 4DELETE FROM user; 5 6// Delete a specific user 7DELETE FROM user 8WHERE ssn = '342-45-6732';
Data Integrity
One problem that often plagues databases is ensuring the integrity of their information. Sometimes the data is so delicate and sensitive that adding a zero to an integer, for example, could simply end up making someone a millionaire.
To ensure integrity, we need to follow the following rules:
- Unique user columns: This will avoid having users with the same email, the same social security number, etc.
- Using foreign keys (restrictions): This will avoid having a baseball player on a team that does not exist, for example.
- Specify default values and which columns can be NULL in the table's definition.
- Use enumerations: These are great for setting the possible values of a column. For example, if we had a "Sex" column on a person, a good enumeration might be "Male", "Female", "No answer".
- Using transactions (commit and rollback): We'll talk about that next. Transactions are a good way to roll back in time if something goes wrong.
Transactions
A transaction is a sequence of operations (such as INSERT, UPDATE, SELECT) performed on your database. For a transaction to be complete, all operations must be successful. If one operation fails, the whole transaction fails.
All transactions must ensure 4 main properties (known as ACID properties): Atomicity, Consistency, Isolation and Durability.
SQL Transactions
Transactions in SQL are controlled by several statements:
- COMMIT: Used to save changes.
- ROLLBACK: Used to revert changes.
- SAVEPOINT: Creates a checkpoint within groups of transactions from where you can return with a
ROLLBACK. - SET TRANSACTION: Name a transaction.
Transaction control commands are only used with the DML INSERT, UPDATE and DELETE commands. They cannot be used when creating tables or deleting tables because these operations are automatically committed to the database.
COMMIT statement
The COMMIT command is used to permanently save changes made to a transaction within the database. When you use INSERT, UPDATE or DELETE, the changes made with these commands are not permanent; the changes made can be undone or, in other words, we can go back.
However, when you use the COMMIT command, the changes to your database will be permanent.
The syntax for the command is as follows:
1// Operation one... 2 3// Operation two... 4 5// Operation three... 6 7COMMIT;
ROLLBACK statement
The ROLLBACK command restores your database to your last COMMIT. You can also use it with the SAVEPOINT command to jump to a point you have saved during an ongoing transaction.
The syntax for the command is as follows:
1// Any operation before the ROLLBACK 2INSERT INTO client_account SET (amount) VALUES (1000) 3 4// Now we ROLLBACK the transaction, the INSERT never happened 5ROLLBACK;
SAVEPOINT statement
The SAVEPOINT command is used to temporarily save a transaction so that you can return to a certain point using the ROLLBACK command if you need to.
The syntax for the command is as follows:
1SAVEPOINT savepoint_name;
This command is only used to create a SAVEPOINT between transactional statements. The ROLLBACK command is used to undo a group of transactions.
The syntax for the command is as follows:
1ROLLBACK TO savepoint_name;
The RELEASE SAVEPOINT command is used to delete a SAVEPOINT that has been previously created.
The syntax for the command is as follows:
1RELEASE SAVEPOINT savepoint_name;
SET TRANSACTION statement
The SET TRANSACTION command is used to start a database transaction. This command is used to specify characteristics for the next transaction. For example, we can specify a transaction to be read-only or read-write.
The syntax for the command is as follows:
1SET TRANSACTION [ READ WRITE | READ ONLY ];